For me SmartScoring has been the worst way to follow LIVE scores at a Gymnastics competition.
And it seems to fail. Regularly.
Some people like LiveMeet, which is what we use in Canada. Personally I find the interface unappealing and slow. It’s like a webpage from the 1990s.
Longines is pretty. But I’m often confused with the layout.
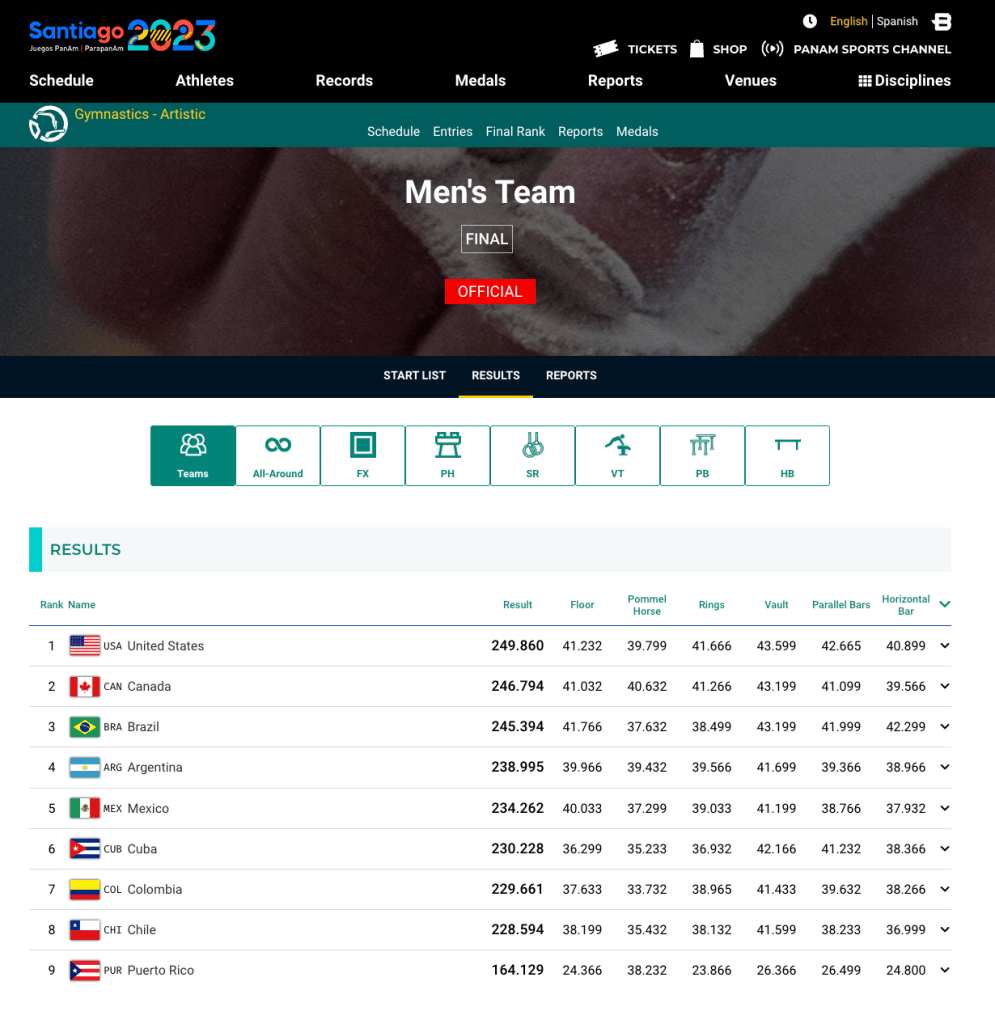
Rachael points out that the system used for the PanAm Championships is quite good. A very clear and intuitive interface than anyone can use instantly. And it includes a lot of data.
After Rebeca scored 9.733 execution on what many would consider a perfect Cheng, there has been discussion online. 😀
ALL agree that FIG judges in 2023 “box” the execution scores too much. The difference between best and worst is not accurately reflected by differences in E score.
Judges do this in order to stay in range, and not get in trouble from the FIG WTC.
Personally, I’d like to see the rare 10.0 execution score. (Certainly there are too many in WAG NCAA, some obviously not even close to being deserved.)
IF the performance is significantly superior to anyone else in the world — and there are no obvious deductions — it should get a 10 execution score.
I’ve seen several P Bar routines from Zou Jingyuan where I would have NO DEDUCTIONS recorded on my judging sheet. For example.
my feelings on the 10e discussion aside i will NEVER miss an opportunity to make people watch the closest thing to absolute perfection we’ve seen that isn’t a vault ❤pic.twitter.com/YnkYW0WqyDhttps://t.co/OhZ1M4zgNF